General Detection-based Text Line Recognition
(NeurIPS 2024)

Abstract
We introduce a general detection-based approach to text line recognition, be it printed (OCR) or handwritten (HTR), with Latin, Chinese, or ciphered characters. Detection-based approaches have until now been largely discarded for HTR because reading characters separately is often challenging, and character-level annotation is difficult and expensive. We overcome these challenges thanks to three main insights: (i) synthetic pre-training with sufficiently diverse data enables learning reasonable character localization for any script; (ii) modern transformer-based detectors can jointly detect a large number of instances, and, if trained with an adequate masking strategy, leverage consistency between the different detections; (iii) once a pre-trained detection model with approximate character localization is available, it is possible to fine-tune it with line-level annotation on real data, even with a different alphabet. Our approach builds on a completely different paradigm than state-of-the-art HTR methods, which rely on autoregressive decoding, predicting character values one by one, while we treat a complete line in parallel. Remarkably, we demonstrate good performance on a large range of scripts, usually tackled with specialized approaches. We surpass state-of-the-art results for Chinese script on the CASIA v2 dataset, and for ciphers such as Borg and Copiale, while also performing well with Latin scripts.
Method
Given an input text-line image, our goal is to predict its transcription, i.e., a sequence of characters.
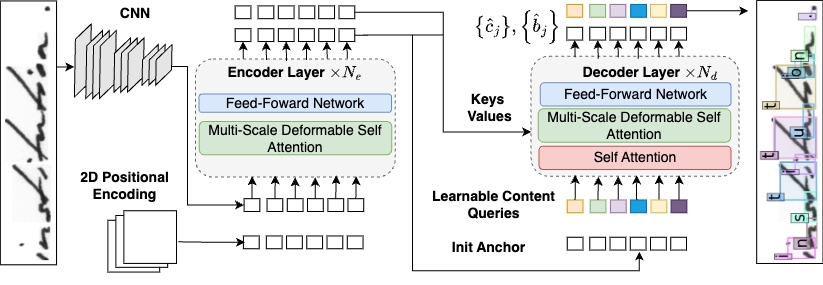
We tackle this problem as a character detection task and build on the DINO-DETR architecture,
shown in the Figure below, to simultaneously detect all characters.
Qualitative Results
IAM




READ




RIMES




Copiale


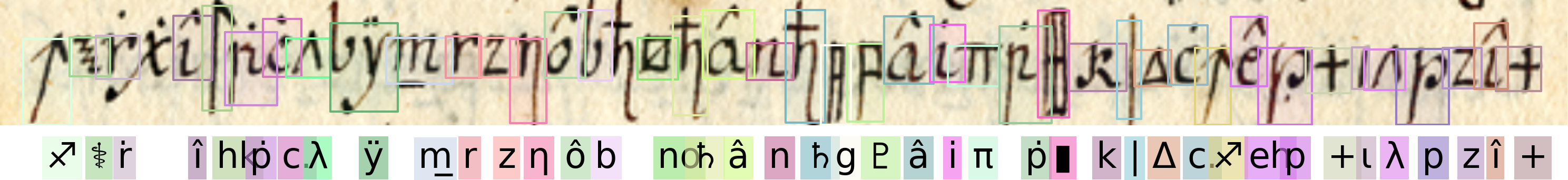
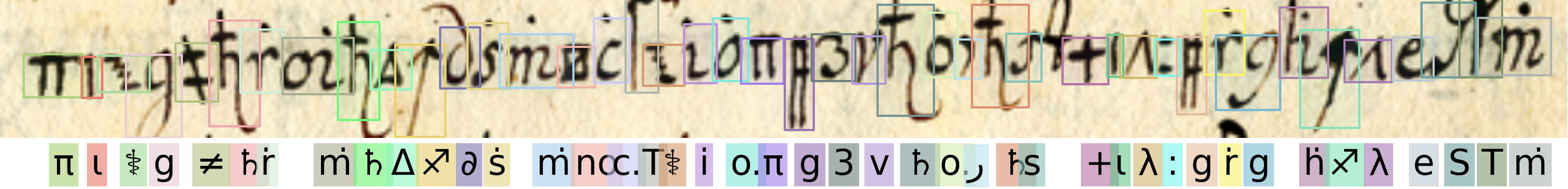
Acknowledgements
This work was funded by ANR project EIDA ANR-22-CE38-0014, ANR project VHS ANR-21-CE38-0008, ANR project sharp ANR-23-PEIA-0008, in the context of the PEPR IA, and ERC project DISCOVER funded by the European Union’s Horizon Europe Research and Innovation program under grant agreement No. 101076028. We thank Ségolène Albouy, Zeynep Sonat Baltacı, Ioannis Siglidis, Elliot Vincent and Malamatenia Vlachou for feedback and fruitful discussions.
BibTeX
@article{baena2024DTLR, title={General Detection-based Text Line Recognition},
author={Raphael Baena and Syrine Kalleli and Mathieu Aubry},
booktitle={NeurIPS},
year={2024},
url={https://arxiv.org/abs/2409.17095}}